Can you think of a time where you forgot to make a backup of a file/folder, and accidentally corrupted or deleted it? Maybe a mistaken command ran ‘rm -rf’ across your entire music library? Maybe core system files of a virtual machine were corrupted? We all make mistakes, and the sooner you move to ZFS, the sooner you can stop worrying about making them with your personal data.
See Also: Every VFIO Newbie Should Get a KVM USB Switch
Installing and configuring ZFS on Linux is very easy for most distributions.
Arch
It is generally better to use “zfs-linux-git” as kernel updates will be very fast. Compile it with your favorite AUR helper, then enable the service:
yaourt -S zfs-linux-git # for yaourt users pacaur -S zfs-linux-git # for pacaur users sudo systemctl enable zfs.target sudo systemctl enable zfs-import-cache sudo systemctl enable zfs-mount sudo systemctl enable zfs-import.target
It is also possible to compile AUR packages without a helper at all if you desire. If the install is successful, after a reboot ZFS should be ready to use. More information can be found on the Arch Wiki.
Debian
Debian makes it even easier to use ZFS – as long as one has the contrib repository enabled, it is an apt install away. Ensure your /etc/apt/sources.list has the repository enabled:
deb http://mirrors.kernel.org/debian/ stretch main contribNext install ZFS:
sudo apt update sudo apt install linux-headers-$(uname -r) zfs-dkms
Apt automatically enables the systemd services, so all that you must do is reboot.
Ubuntu
From Xenial onwards, Ubuntu includes the ZFS kernel module. All you need to do is add the userland tools as such and reboot:
sudo apt install zfsutils-linux
Fedora
Courtesy of the ZFSOnLinux Wiki, Fedora users can install ZFS with a few simple commands:
sudo dnf install http://download.zfsonlinux.org/fedora/zfs-release$(rpm -E %dist).noarch.rpm gpg --quiet --with-fingerprint /etc/pki/rpm-gpg/RPM-GPG-KEY-zfsonlinux sudo dnf install kernel-devel zfs
These commands add the ZoL repository on the system and install the ZFS module.
Gentoo
Being a source-based distribution, ZFS on Gentoo does not require DKMS. To install it, first ensure your kernel has Deflate compression support. In “make menuconfig” enable it:
Cryptographic API -->
<*> Deflate compression algorithmNext, allow the git versions of ZFS to be used by running the following commands as root:
echo "=sys-kernel/spl-9999 **" >> /etc/portage/package.accept_keywords/zfs echo "=sys-fs/zfs-kmod-9999 **" >> /etc/portage/package.accept_keywords/zfs echo "=sys-fs/zfs-9999 **" >> /etc/portage/package.accept_keywords/zfs
Finally, install and enable ZFS:
sudo emerge -a =zfs-9999 # For OpenRC users sudo rc-update add zfs-import boot sudo rc-update add zfs-mount boot # For systemd users sudo systemctl enable zfs-mount sudo systemctl enable zfs-import
If you are running Gentoo Hardened, you may need to disable certain kernel settings. Consult the Gentoo Wiki for more information.
Creating a ZFS “partition”
Now that you have installed the filesystem, you will need to make a pool. Pools can get very complex, spanning across many drives and offering redundancy. However, in this example one partition without redundancy will be used. First, an empty partition is required. ZFS is possible to use as a root filesystem on Linux, but it is usually ill-advised. Repartition another drive using your preferred partition managing tool, such as GParted. If you are resizing your root filesystem to make room, you will need a live disk such as the GParted Live Disk.
Afterwards, run the following command to create a new zpool:
sudo zpool create -m /your/mount/point yourpoolname /dev/sdXY
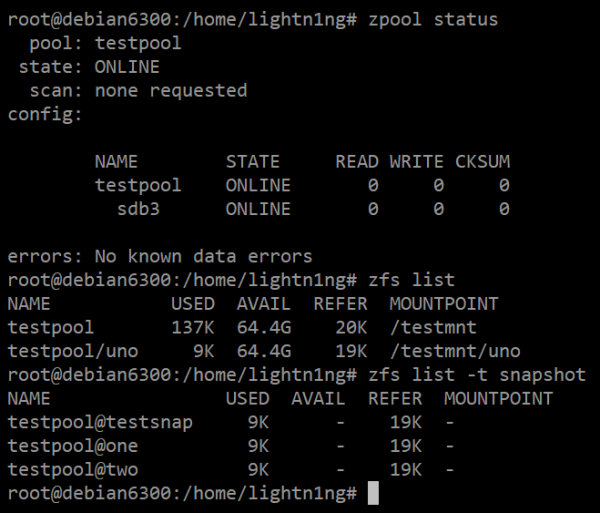
Basic Usage
ZFS has the idea of a dataset – essentially a mini-partition within a ZFS volume. You can mount datasets at any location you desire. When you take a snapshot, you are taking a snapshot of a dataset. To create a dataset, run the following command:
sudo zfs create -o mountpoint=/your/mount/point/dataset1 yourpoolname/dataset1
You can, of course, change the mountpoint and dataset name to whatever you desire.
The prime focus of this article has been snapshots – it would be a waste if I didn’t explain those, wouldn’t it? To create a new snapshot, run the following command:
sudo zfs snapshot yourpoolname/dataset1@snapshotname
ZFS allows a virtually unlimited number of snapshots per dataset. Unfortunately, reverting to an older snapshot requires deleting all snapshots created after it. To rollback to an older snapshot:
sudo zfs rollback yourpoolname/dataset1@snapshotname
Another useful feature of the filesystem is the clone feature. Clones allow you to duplicate a dataset without actually occupying all of the disk space a second time. All writes to either dataset will use additional space, of course. You must snapshot a dataset before you can clone it. To clone a dataset, run:
sudo zfs list -t snapshot # List all available snapshots sudo zfs clone yourpoolname/dataset1@snapshotname yourpoolname/clonename
To destroy a snapshot:
sudo zfs destroy yourpoolname/dataset1@snapshotname
To destroy a dataset, including a clone:
sudo zfs destroy yourpoolname/clonename
One interesting and relevant use case of ZFS is virtualization – storing a VM image file on a dataset allows easy rollbacks and clones with minimal performance overhead.
ZFS is a very powerful filesystem with an enormous amount of features. As it is impossible to even begin to explain them all in one article, I will link you to FreeBSD’s fantastic documentation. While written for FreeBSD, most of it will also apply directly on Linux (as well as OSX, IllumOS and tentatively, Windows). I recommend getting familiar with the idea of datasets if you intend on using ZFS.
Not in our Discord yet? Join us to chat with other VFIO users and get support! Want to build a VFIO gaming rig? Check our VFIO Increments page for advice and parts recommendations.
Images courtesy PixaBay